
Incentivizing both Grounding and Reasoning in Large Language Models with Online Reinforcement Learning
| Link to Full Report | View on GitHub |
A Group Thesis Project Exploring Reasoning, Grounding, and Learning Efficiency in AI Agents
This project was undertaken as our thesis for the course on Open-endedness and General Intelligence, taught by Tim Rocktäschel (Google DeepMind & UCL), Roberta Raileanu (Meta GenAI & UCL), and Jack Parker-Holder (Google DeepMind & UCL).
Our work explored whether prompting Large Language Models (LLMs) to “reason” before acting improves their learning speed and generalization in complex text-based environments. We developed and fine-tuned LLM agents using a novel token-by-token action generation method and a nested Reinforcement Learning (RL) approach within the BabyAI-Text platform.
The Core Question & Our Approach
Can explicit reasoning enhance LLM agent performance in online RL? We tackled this by:
- Developing LLM agents that generate actions token-by-token, offering greater flexibility.
- Comparing agents that verbalize reasoning steps against those generating actions directly.
- Implementing a nested PPO-based RL algorithm for fine-tuning (using LLaMA-3.2-3B-Instruct with LoRA) to precisely assign credit during the decision process.
- Testing in BabyAI-Text, a text-based environment requiring language understanding and navigation.
Key Findings & Impact
- Reasoning Didn’t Boost Performance: Surprisingly, explicit reasoning did not significantly improve sample efficiency or task success rates in the tested scenarios.
- Interpretability Without Cost: Crucially, reasoning-based agents provided valuable insights into their decision-making process without compromising effectiveness, a key benefit for AI transparency and debugging.
- Identified “Reasoning Collapse”: We observed instances where articulated “thoughts” devolved into simply restating the intended action.
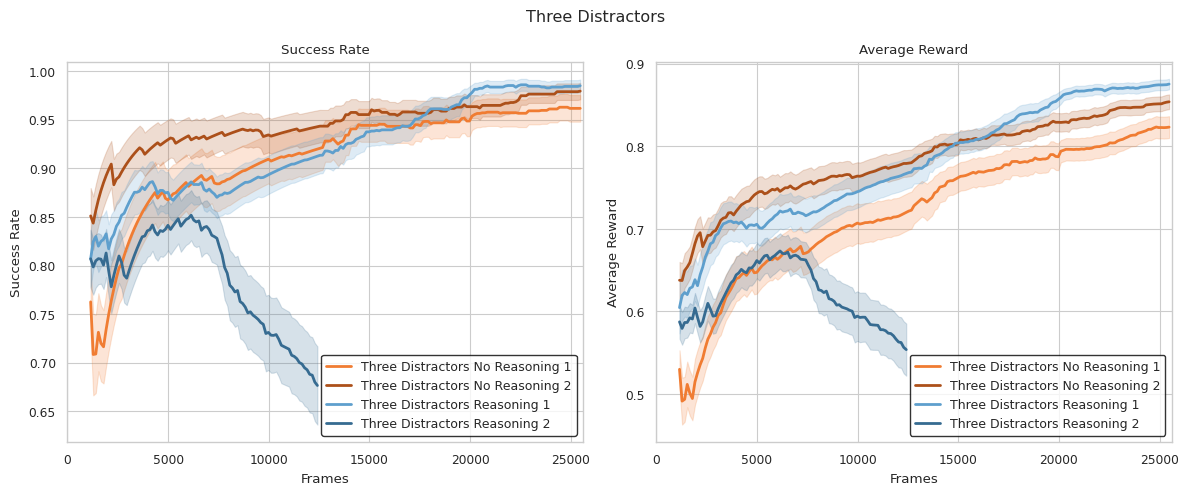 Caption: Training curves showing success rate and average reward for the medium difficulty environment with 3 distractors. Both agents (reasoning and non-reasoning) improved through RL fine-tuning. The reasoning agent (shades of blue) performed comparably to the non-reasoning agent (shades of orange), with added training instability (as indicated by the tanking blue curve) but also potential interpretability benefits.
Caption: Training curves showing success rate and average reward for the medium difficulty environment with 3 distractors. Both agents (reasoning and non-reasoning) improved through RL fine-tuning. The reasoning agent (shades of blue) performed comparably to the non-reasoning agent (shades of orange), with added training instability (as indicated by the tanking blue curve) but also potential interpretability benefits.
Technical Highlights
- Languages & Frameworks: Python, PyTorch, Hugging Face Transformers, TRL, PEFT
- Core AI/ML: Reinforcement Learning (PPO, Nested RL), LLM Fine-Tuning (LLaMA, LoRA), Prompt Engineering
- Environment & Tools: BabyAI-Text, Weights & Biases, Hugging Face Hub, Git
Skills Showcased (Group Effort)
- Advanced RL Algorithm Design & Implementation
- LLM Fine-Tuning & Adaptation
- Experimental Design & Data-Driven Analysis
- Collaborative Software Engineering for AI Research
- Critical Problem-Solving & Team-Based Inquiry
This project demonstrates our collective ability to innovate at the intersection of LLMs and RL, rigorously test hypotheses as a team, and extract valuable insights even from unexpected results. We faced multiple hurdles along the way which we overcame through collaboration, iterative problem-solving, and commitment to our research goals.
Explore Further:
- Code: GitHub Repository
- Full Paper: Project Report
- Connect: LinkedIn